
Funky Si walks a half marathon
Funky Si walks a half marathon

I was recently invited onto the TrekRanks podcast
Make API calls from Visual Studio or Visual Studio Code

Become the best Actor, Astronaut or Developer you can be
On Saturday 7th October I attended DDD East Midlands

Last night I had a bit of a chat about season 3 of Star Trek Picard
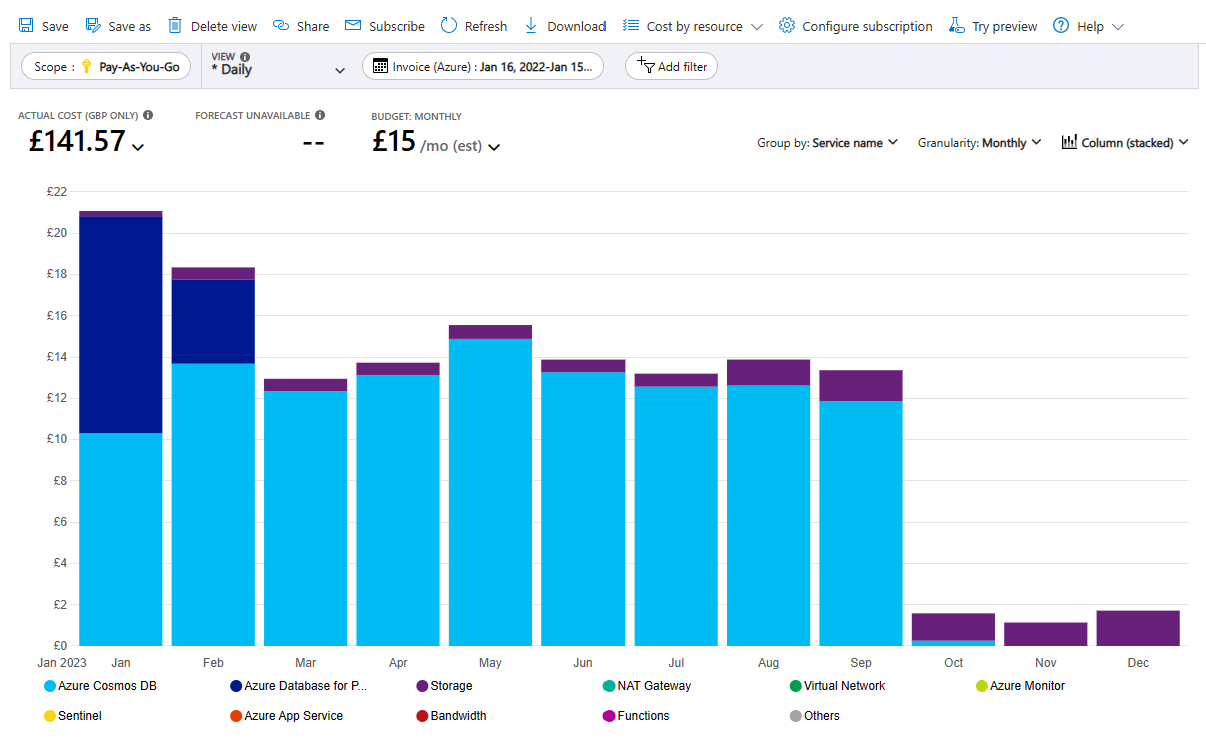
How much does it cost?

I love listening to podcasts so I thought I would share what I have been listening to over the last few days

I love listening to podcasts so I thought I would share what I have been listening to over the last few days

As 2022 draws to a close its time to do my annual look back at what happened