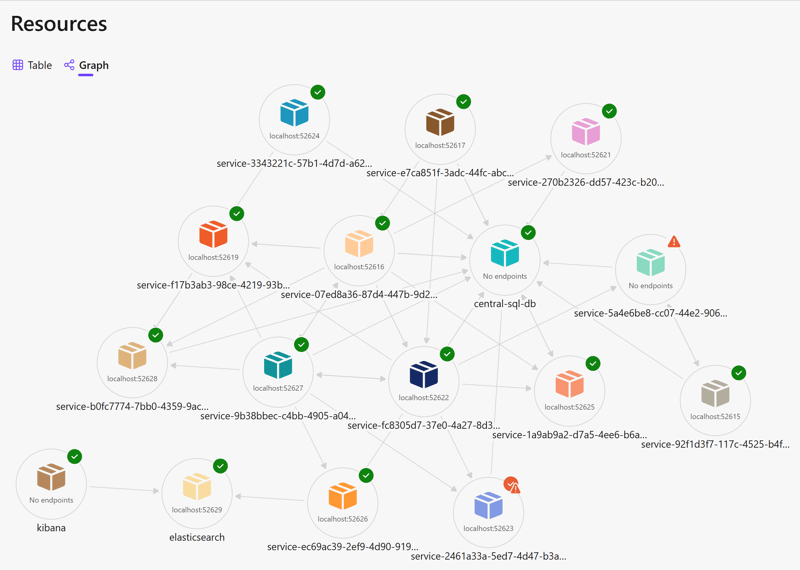
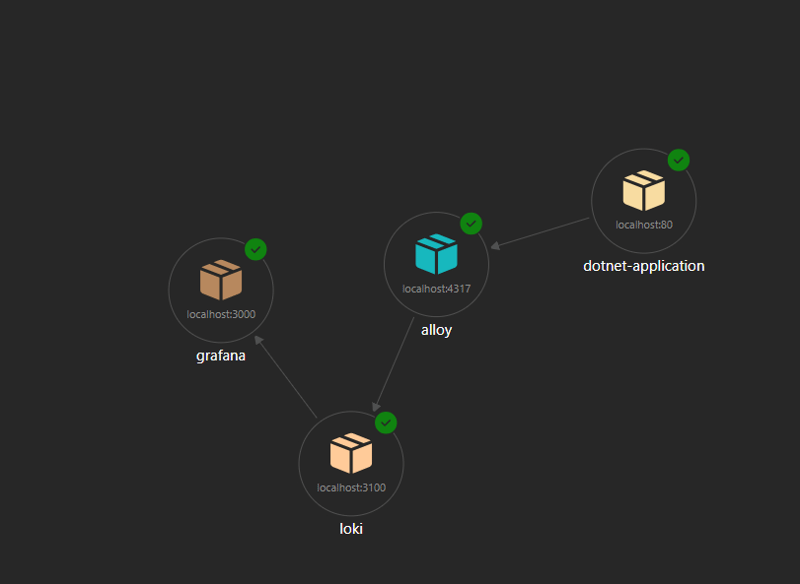
I have blogged before about how cool Let’s Encrypt is for getting your web things running under https. However I have just got myself a local kubernetes cluster and it is super easy to spin up new web services with SSL certs. The basic instructions can be found here but let’s look at what was involved. First of all...